22 July 2020
Last week, I joined the UIUCTF with my juniors again to kill some time. To my pleasant surprise, the CTF had a decent number of pwn challenges and the difficulty for the challenge I solved, MuJS, was sufficiently high. It was pretty interesting as this Javascript Engine was not one of the conventional engines used in browsers, but rather an independent engine built from scratch. Tldr for writeup: Integer overflow -> Heap buffer overflow -> Type confusion -> OOB -> arb RWX, exploit linked in conclusion
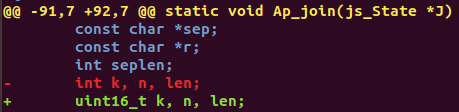
At the start of attempting the challenge, I almost immediately made the mistake of ignoring the README.txt file and pulled out the Fuzzili fuzzer as I thought we were supposed to find a 0-day in the latest commit of MuJS. After all, the challenge had 0 solves when I started, which was unusual for good CTFs with strong players. Silly me. From the README.txt file, I noticed this challenge is unique in that instead of aiming for RCE, our goal was to gain a stable arbitrary read write and execute primitive in the MuJS engine across unknown setups and architectures. This meant that the standard techniques of overwriting Glibc hooks or running shellcode were a lot less effective, if not impossible. Keeping that in mind, I did a git diff as instructed and focused on jsarray.c. The following single line of edit is seen:
 The bug
The bug
The vulnability shown here is similar to the recent series of critical windows vulnerabilities such as SMBGhost and SIGRed. That is, the sizes of data are being truncated to a smaller integer type when passed to memory allocation routines, resulting in the buffer allocated in some cases to be too small to hold the data, thus leading to a heap buffer overflow. Here, the modification reduced the signed 32 bit integers to unsigned 16 bit, which meant they would wrap back to 0 once their values exceeded 65535.
n = 1;
for (k = 0; k < len; ++k) {
js_getindex(J, 0, k);
if (js_isundefined(J, -1) || js_isnull(J, -1))
r = "";
else
r = js_tostring(J, -1);
n += strlen(r); // Integer overflow
if (k == 0) {
out = js_malloc(J, n); // Too small buffer
strcpy(out, r);
} else {
n += seplen; // Integer overflow
out = js_realloc(J, out, n); // Too small buffer
strcat(out, sep);
strcat(out, r);
}
js_pop(J, 1);
}
Looking through the whole function Ap_join, the variable n interests me the most. It denotes the current length of the output string for Array.prototype.join, and is passed to js_malloc to allocate more memory is needed. If we join an array with a single string of size 65536, n would wrap back to 65536 + 1 = 1 and hence the subsequent strcpy should give us an overflow.
 The crash
The crash
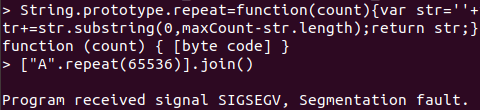
Using a polyfill from MDN for String.prototype.repeat which the engine did not implement, I managed to generate the string and get a crash. But why does the crash happen? We have to investigate what goes under the hood in js_malloc to figure this out.
 my_malloc zones
my_malloc zones
void* my_malloc(int size) {
for (int i = 0; i < NUM_ZONES; i++) {
if (size <= zones[i].allocation_size) {
if (zones[i].free_list_head == NULL) {
fprintf(stderr, "Memory exhausted.");
exit(1);
}
free_list_t* result = zones[i].free_list_head;
zones[i].free_list_head = result->next;
// Unrelated code omitted
return result;
}
}
void* real_result = malloc(size+8);
*(uint64_t*)real_result = size;
return real_result + 8;
}
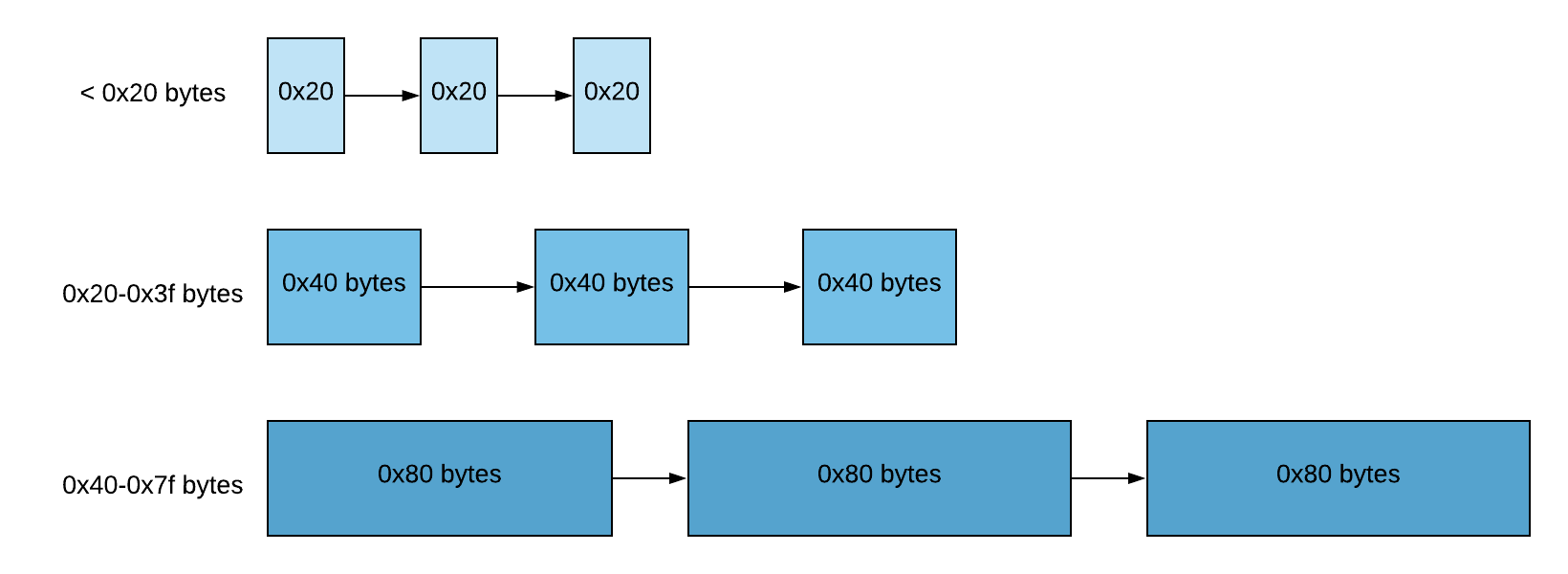
With a bit of tracing, I realised hat instead of using trusty old Glibc malloc, the challenge authors have implemented their own memory management system with a set of functions named my_malloc/free/realloc (they were in the diff but I obviously wasn’t looking carefully). While I was initially pretty annoyed that I would have to grok yet another heap management codebase, it turns out that this memory management system is extremely simple: it groups chunks by size range in what were known as “zones”, which were managed by a singly-linked free list each. The Glibc malloc is only invoked when the size requested exceeds the chunk size upper limit, and exhausting any free-list results in an exit rather than fallback on malloc.
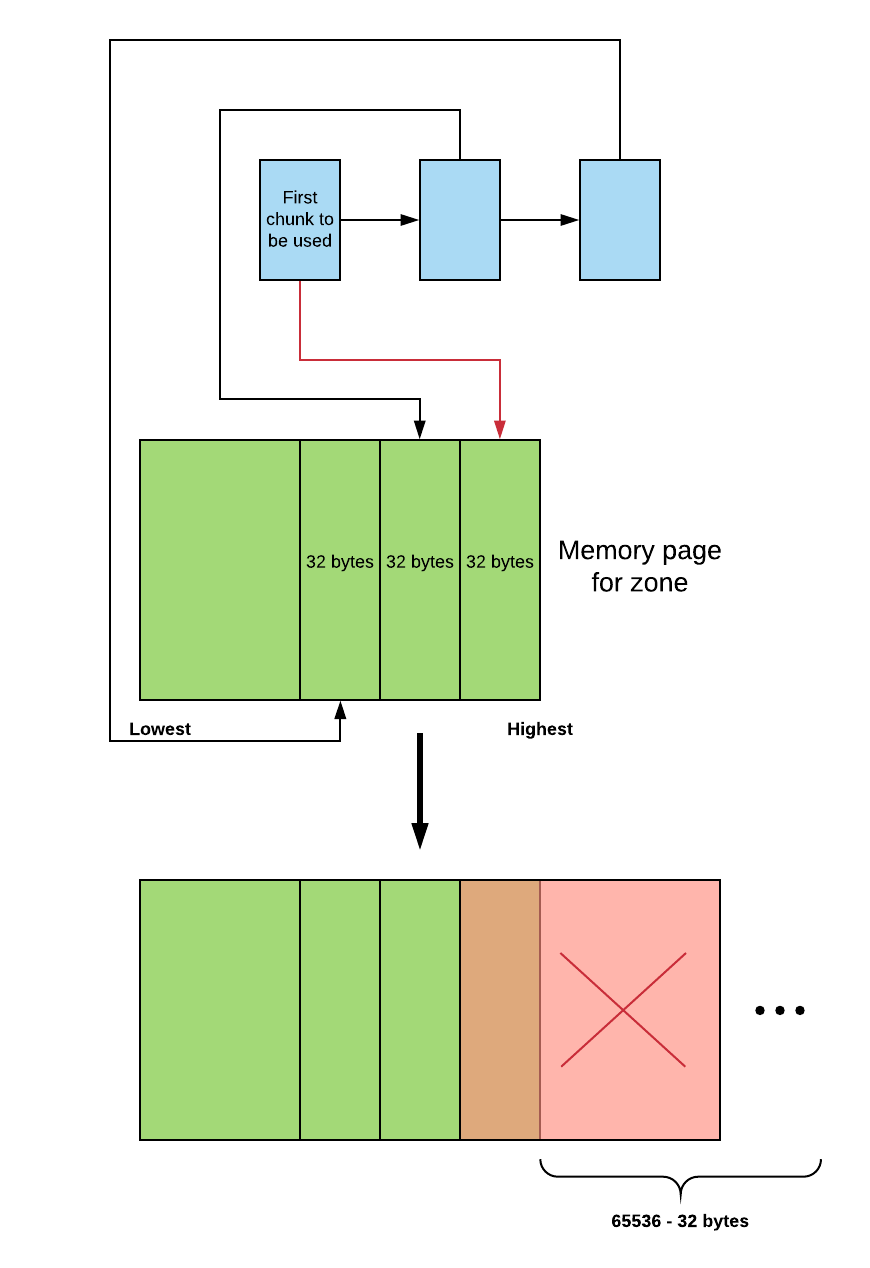 Diagram on crash process; first chunk allocated is last in page, causing write beyond page
Diagram on crash process; first chunk allocated is last in page, causing write beyond page
This system is in fact advantageous in helping us achieve the goal of a platform independent exploit. We could reliably predict heap layout across all setups without worrying about Glibc heap shenanigans such as the TCache. Understanding the memory management system, we come back to the crash. When initialising the free list, the code places the chunk at the lowest address into the list moves upwards. As the malloc code takes chunks out in a FILO order, the first chunk that got allocated to us was right at the end (to be precise, 32 bytes away) of the zone’s memory page. The overflow thus led to an out-of-bound write on the memory page, leading to the crash.
Having a habit of formulating a rough plan before exploitation, I was now planning to use this overflow to cover the heap with my string, then allocate objects to overwrite the string, thus granting me a leak that may turn up handy. However, when analysing the source code to understand the general structure of the engine, something caught my eye.
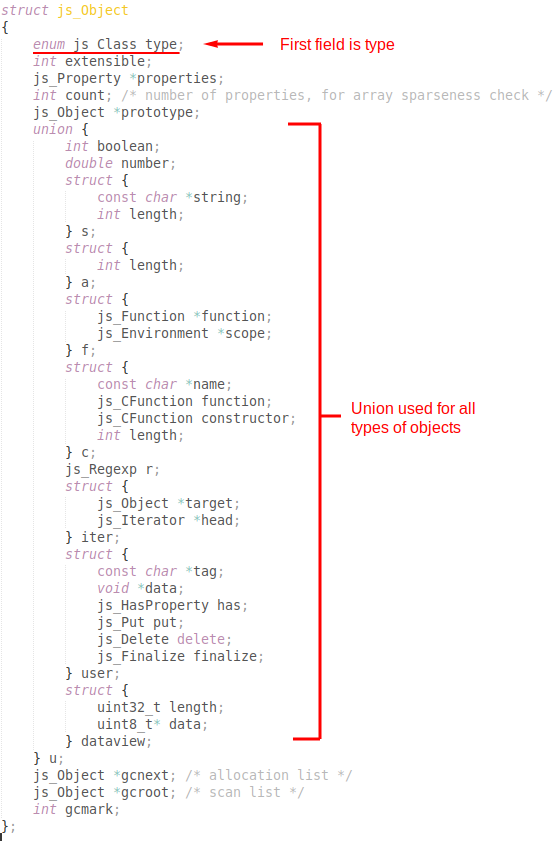 Struct of interest
Struct of interest
The above struct is used for all JS objects (i.e. non primitive types). Notably, different objects share this same struct through a union. More importantly, the first single field of an object represents its type in the form of an enum. What this means is that with our linear buffer overflow (i.e. we have to (over)write sequentially), we can modify the type of a JS object while keeping all its other data intact, as they come after the type based on the order in the struct. My previous plan gave way to the obvious superior choice of making use of type confusion.
However, I quickly ran into a wall. The JS object was 0x68 bytes, and hence used chunks of 0x80 bytes. To ensure our chunk that gets overflowed by our string is in the same zone, the string length would be between 65536 + 0x3f and 65536 + 0x7e.
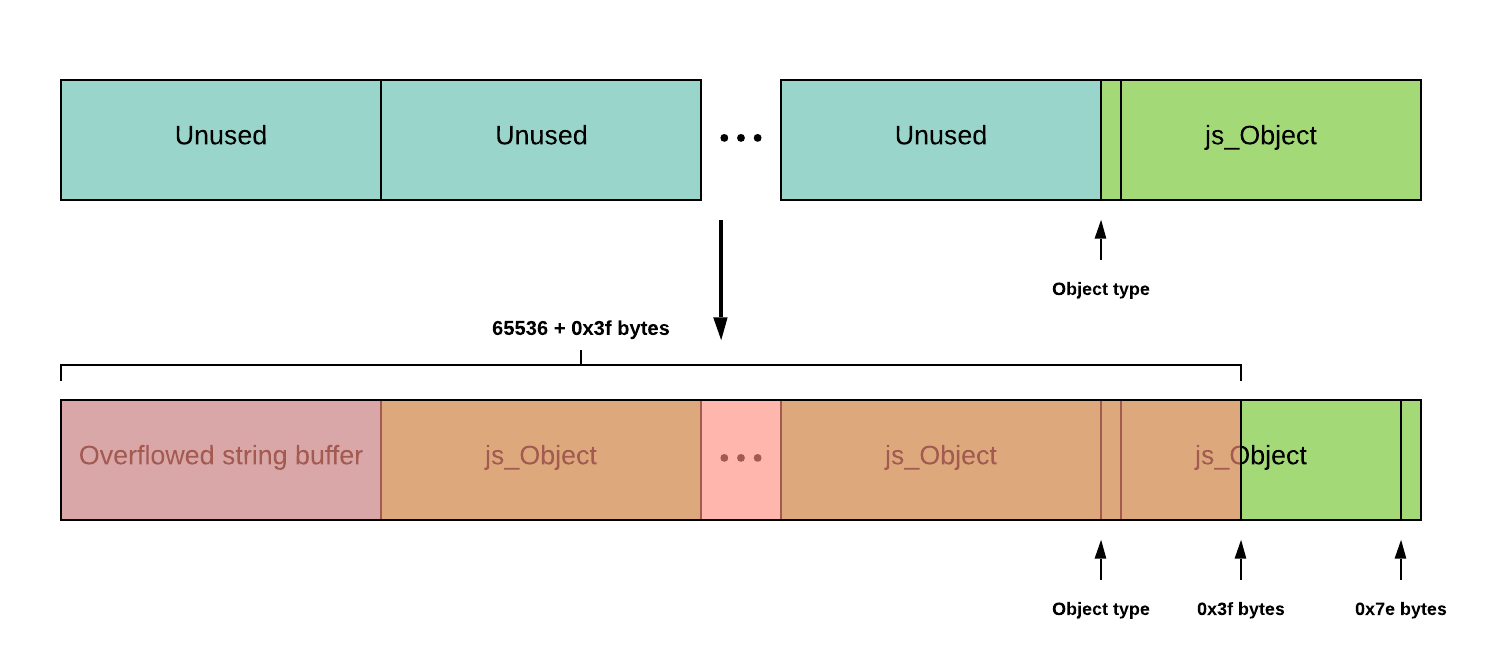 Diagram showing we can never overflow exactly 1 byte into an object’s chunk
Diagram showing we can never overflow exactly 1 byte into an object’s chunk
 This corruption is not viable
This corruption is not viable
The problem may not be obvious in writing but as seen above, we could never get a single byte overflow into a chunk. This is because chunks are fixed in size (0x80 here) and our first 65536 bytes of overflow will cover 65536 / 128 = 512 objects, while the remaining 0x3f-0x7e bytes overflow into an object. The type of the object will therefore become an invalid value out of range of its enum. This would not have been a problem if we could have null bytes in the string, but the use of strcpy and strlen in Ap_join mean that null bytes were out of the question. I was doubtful that my idea of type confusion was even right and decided to go back to the drawing board.
n += strlen(r); // 65534 + 1 + 64 = 63
if (k == 0) {
out = js_malloc(J, n);
strcpy(out, r);
} else {
n += seplen; // 63 + 1 = 64
out = js_realloc(J, out, n); // 64 <= 64 >= 128, so out is 128 (0x80) bytes with 64 bytes of old out's data copied in
strcat(out, sep); // 65 / 128 bytes of out used
strcat(out, r); // 65 + 64 = 129 / 128 bytes used -> 1 byte overflow
}
All this time, I had the idea that since the integer overflow caused 65536 -> 0, we would always get a 65536 byte buffer overflow. It turns out to be incorrect from further inspection of the remaining code, specifically code that handled joining more than 1 element. Our truncated n is passed to my_realloc which internally allocates a buffer of n bytes and copies n bytes from the old to the new buffer. Our separator and next element in list will then be strcat to the new buffer. The new buffer of size n will hence in fact have n+separatorlen+nextelemlen bytes stored inside, resulting in a much more controllable size of overflow than the fixed 65536. For my exploit, I made an array of two strings of size 65534 and 64 respectively.
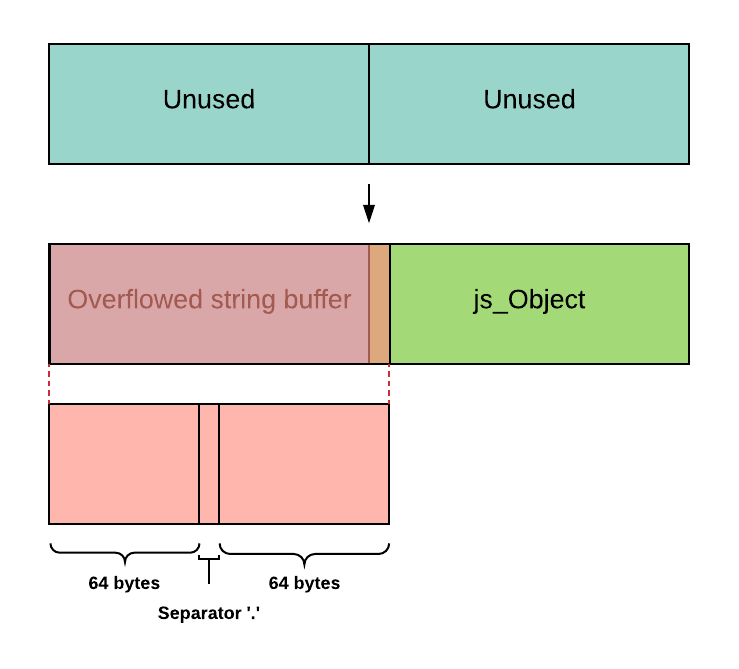 New approach illustrated
New approach illustrated
As illustrated, this will cause a single byte overflow, nicely overwriting the type of an object 0x80 bytes away from our output string. To test our theory, we create a sample object such as an array before calling join. As every subsequent js_malloc returns a chunk of lower address, our output string would be below the sample object and hence overflow into it. From trial and error, the variable that references the object had to defined before assigning the sample object to it. This is because defining a variable creates a variable reference, which takes up an additional 0x80 byte chunk, and we do not want this to mess up our heap layout.
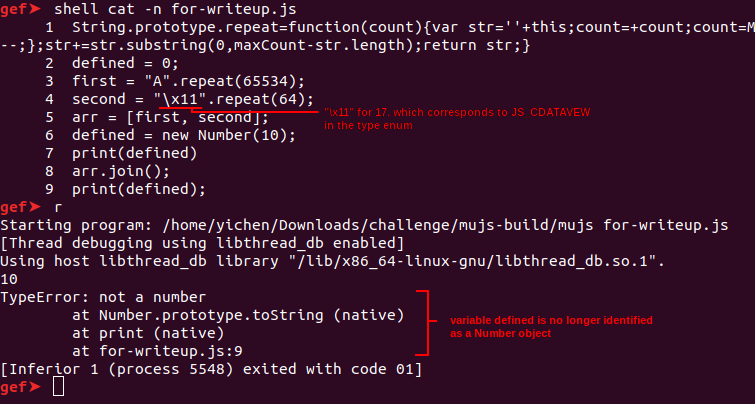 The number object got successfully changed to a DataView
The number object got successfully changed to a DataView
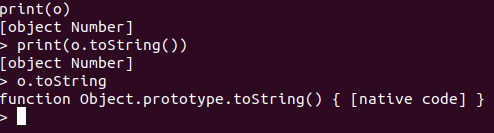 Issue with prototypes
Issue with prototypes
It worked! I then changed a dataview object into a number object, in hopes of getting a leak. No matter what I did, print always printed “[object Number]” instead of its actual value. Experimentation revealed the cause: the prototype in the modified object remained the same, and thus the “number object” still retained its dataview prototype functions, preventing its specialised toString function for number objects to be called.
print(obj) // obj is object type confused to DataView
get8 = DataView.prototype.getUint8.bind(obj); // "this" variable will be set to obj
dataread = get8(0x100); // misusing our type confused DataView
It seemed initially that it is impossible to rectify this issue; the engine was too simple and did not implement builtin functions such as setprototypeof. However, in a random grepping of the source code, I discovered that Function.prototype.bind was present. This function binds an object to a function call, making the this variable point to the object within the function. With this, we can use any of the prototype methods as per normal on our type confusion objects.
 Offset difference between the 2 fields
Offset difference between the 2 fields
Initially, I thought of type confusing the number object into a dataview object, which will result in the object’s integer value being be used as a pointer, causing arbitrary read write. However, I soon discovered that was not possible as the number field was +0 in the union of js_Object but the data pointer for the dataview was at +8. Strings do have a length value at +8, but that cannot be changed into an arbitrarily large value like a pointer, as it is tied to the actual length of string. We could possible confuse an object like function to a dataview and overwrite the function’s internal data structures, but that would be pretty complicated as well.
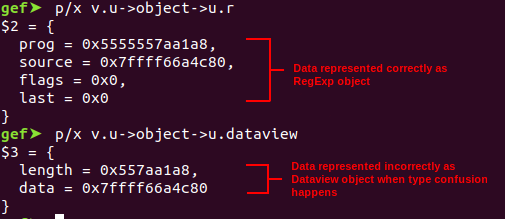 Type confusion from RegExp to DataView
Type confusion from RegExp to DataView
It was then I realised: if we could confuse an object such as a function to a dataview, we could basically read and write out of bound for whichever pointer coincided with the dataview’s data pointer. Because another pointer’s position coincided with the position of length of the dataview in the union, such as js_Function in the case of functions, this meant that our dataview had an enormous length. We would then take a similar approach to conventional Javascript engine pwning, turning an out of bound read write to arbitrary read write by modifying objects in adjacent memory. However, function objects were unsuitable for this task as the field js_Environment was an object that was not in the zone of size range between 0x40 and 0x80, so our OOB RW would not be on the same memory page as the other js_Objects. In this case, regexes were a superior object to confuse into dataviews, as their pointer at +8 was a pointer to its source, which is the string used to make the regex. This meant we could control the size of the chunk pointed by the source and ensure it was in the corect zone.
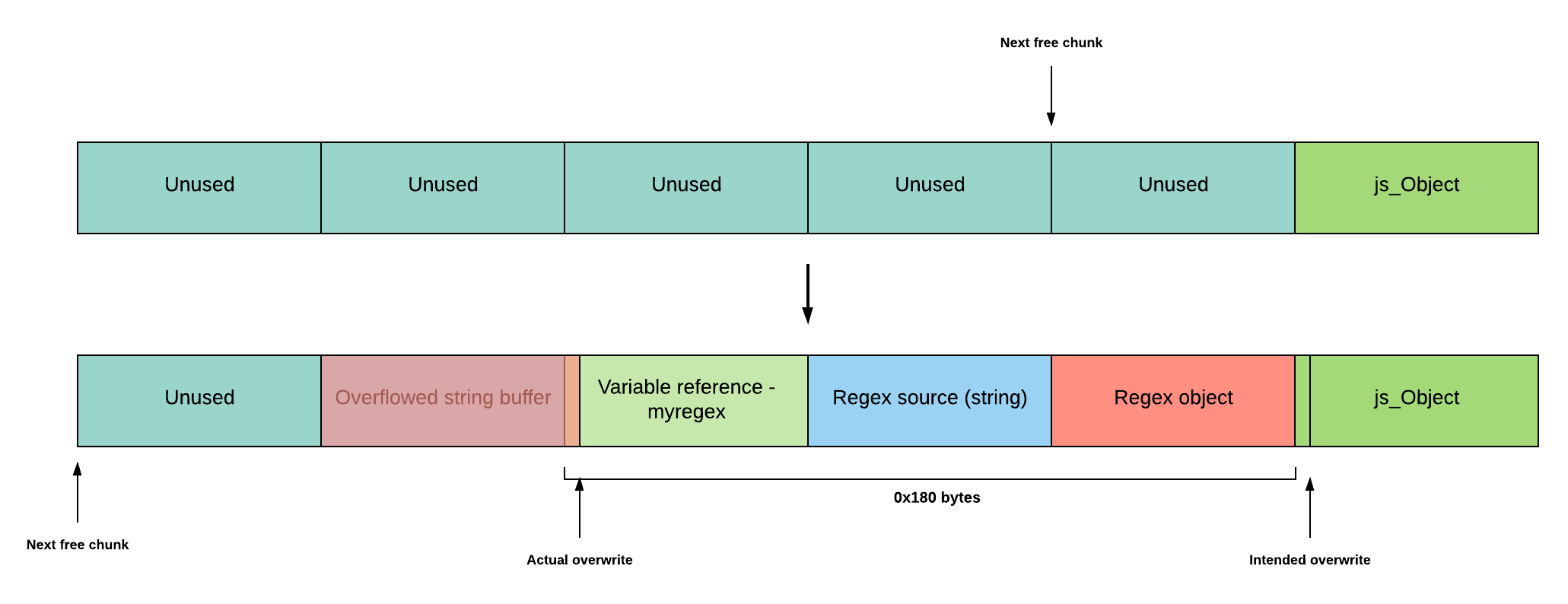 Our current overflow cannot reach the target object
Our current overflow cannot reach the target object
It seems like the exploitation process is coming to an end, isn’t it? As it turns out, there were yet more hurdles ahead. When execute the line myregex = RegExp(str), the js_Object for the regex object is first allocated. A chunk to hold a copy of the string is then allocated, and lastly, an additional chunk is used to hold the variable reference for the variable myregex as previously mentioned. We need the overflowed string buffer and regex object to be 0x80 bytes apart only, but the previously mentioned allocation process meant the gap would be 0x180 bytes instead.
Pondering upon this problem, I then realised something I have ignored all along: freeing data! When we use the Javascript keyword “delete” to delete variables, we remove their variable references, hence freeing up 0x80 bytes for every delete. For our issue of the 0x180 byte gap, we could delete 3 variables right before creating our regex as shown in the graphic. This will prevent the allocation of the regex string and variable reference from using new chunks from the zone and instead reuse those from deleted variables, hence maintaining the gap of 0x80.
 Sample binary search tree
Sample binary search tree
Unbelievably, yet more issues arise. While I thought deleting variables would just free the variable reference objects normally, it instead seem to free additional variable references. After digging into the variable deletion code under the function aptly named “delete”, I recognised a very familiar pattern: a binary search tree (BST). Here, variable references are stored in a simple BST using the strcmp function for comparison.
 BST setup
BST setup
As such, I named all my variables in a sequential naming convention of aa, ab and so on, based on their position in the code. This ensures that our BST becomes like a linked list, whereby deleting the last variable created will remove a leaf node and not a branch from the tree, preventing further memory operations from tree rebalancing which may spoil our memory layout. Furthermore, as existing variable references exist from builtin Javascript code ran by the interpreter, I prepended zzz to all the variable names to make our variables a rightmost subtree with no nodes from outside of our script.
 Error on exit
Error on exit
 Backtrace of error
Backtrace of error
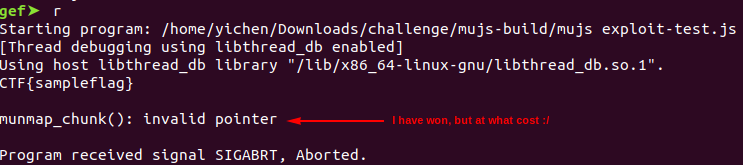
Now, we are finally ready for the exploitation! After our type confusion successfully transmuted the RegExp into a DataView, we can use it to freely read and write on the zone’s memory page. To achieve arbitrary read write, I chose to edit the data pointer of a dataview object I have created beforehand. One thing to note is that if the server binary crashes, no flag would be shown even if it has been printed out on the server side. One way a crash may happen here is due to the MuJS engine doing a garbage collection before exit, which calls my_free on the data pointers of each dataview object. If our modified pointer remains there, my_free will not recognise it as within any zone, thus calling Glibc’s free on the invalid pointer, causing an abort. As such, write32 and read32 should restore the pointers to their original value after use.
 My method of getting code exec
My method of getting code exec
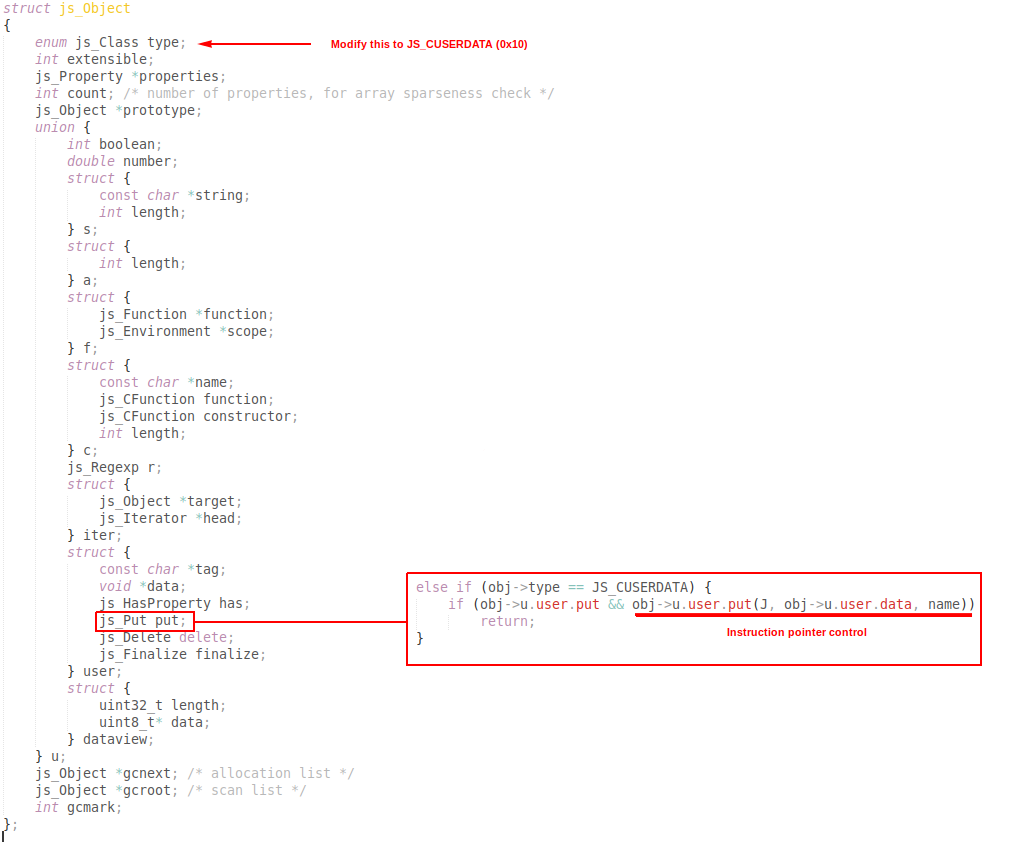
After reading ptrYudai’s awesome writeup here, I realised that the solution to get code execution had room for creativity. While ptrYudai chose to look for a builtin and overwrite its function pointer, my approach was a little simpler. MuJS introduces its own type of object called userdata. This type of object allows C coders to introduce their own object types in MuJS by adding callbacks for different interactions with an object. For example, the put field is a pointer to a function that will be called everytime a property is set on the object. As there userdata objects cannot be created directly from Javascript, I simply made an object and used the OOB write to change its type to userdata, and then point its put field to the location where we want to execute. Then, all I had to do was to add a property for the execution flow to be transferred as intended.
 Pwned ;)
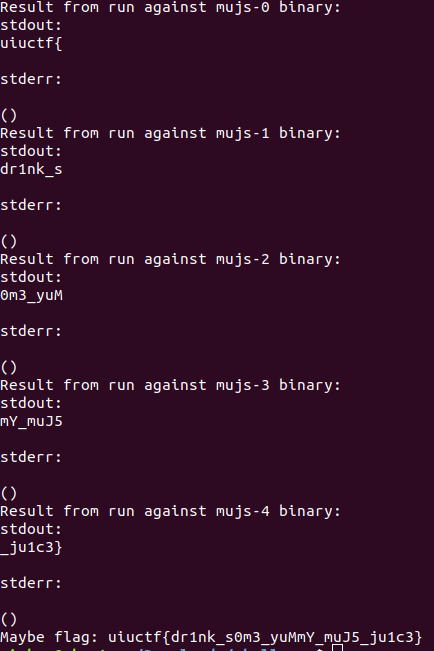
Pwned ;)
Unlike normal pwn where there is only so much code to work with in the small challenge binary, this challenge gives us the freedom to make use of any part of the real life codebase to our advantage, which I liked a lot. As usual, this “writeup” is more of a rambling of my thought process throughout tackling this challenge. As such, here is my exploit for the challenge for any curious souls that are keen on testing it out for themselves. Have a great day!